During Projection 1, I realized that although the “UI + instruction manual” structure could demonstrate how image scripts are deconstructed and executed, the scope of the project was still too broad.
Whether focusing on tourist photos, café images, or lifestyle content, each category involved different platform cultures and behavioral logics. As a result, the system felt more like a generalized classification or description, rather than a focused investigation into how images organize behavior.
So,I get a new plan:
This project takes tourist photographs on social media as its subject, exploring how images, through repetition and circulation, gradually evolve into a form of behavioural discipline. By collecting and analysing 100 images centred on different landmarks such as Big Ben, the project investigates how popular images on social media form a set of stable and repeatable visual templates, and how these templates control the behaviour of image-makers.
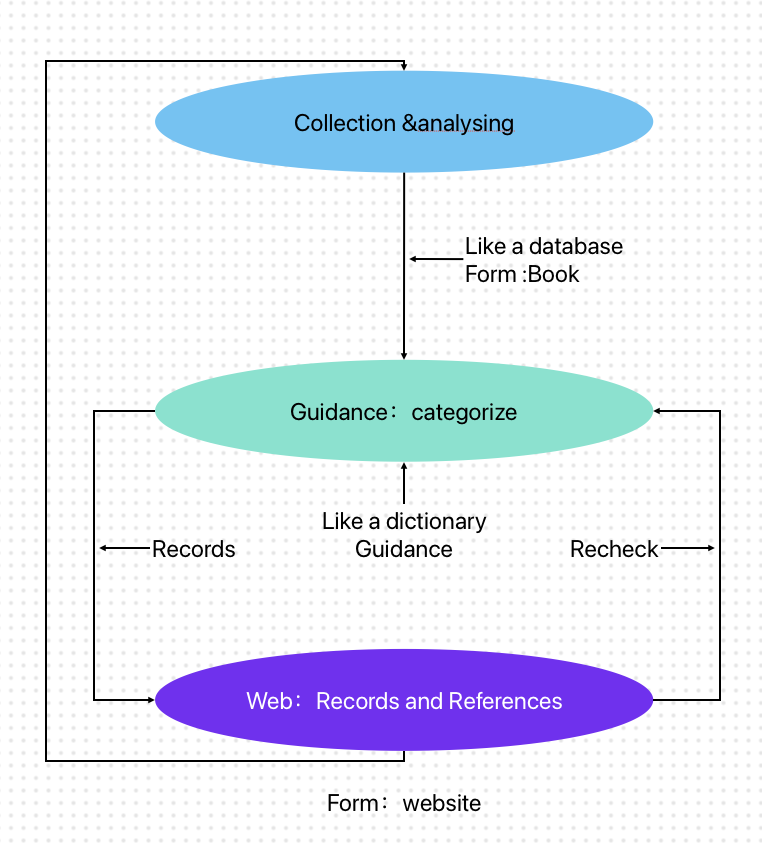
In the first part, I collect and analyse 100 popular tourist photos from social media from different locations and break them down into key elements, like location, environment, people, objects, composition, and camera mode. By comparing them, I start to notice repeating patterns—what I call “image templates” and underlying “visual instructions.”
In the second part, I take the image database from Part 1 and start organising and categorising the different elements. Then I translate these patterns into a system of “image instructions” that people can search and combine.
Viewers can choose from different categories and mix them together to create their own imagined tourist photo. In this process, the image is no longer just the final result—instead, it becomes something like a set of instructions or a script that can be followed.
So this part is really about shifting from analysing images to actually generating image scripts.
In the third part, the project translates the “image instruction guidance” into an online platform. Viewers can select and combine keywords from the Part 2 manual to generate their own image instructions, which are then recorded in the system. At the same time, the platform continuously collects and displays all “generated instructions” in real time.
Through this setup, I want viewers to be both users and producers. While they’re creating what feels like their own instructions, they’re also influenced by what others have already made—often without realising it.So they might end up referencing, imitating, or repeating similar choices. Through this process, the project shows how these image instructions keep being generated, shared, and reinforced through people’s participation.
But Matthew’s approach, which I believed in, allowed me to focus solely on collecting tourist photos of Big Ben, making the locations more specific and narrowing the scope.
Then, I started my Projection 2
Leave a Reply